AI is Supercharging the Iteration Economy
Why Iteration Velocity beats Planning Precision, and Why Old Planning Cycles are an Extinction Event
Christian J. Ward
Oct 27, 2025
This week has been an insane demonstration of something that Naval Ravikant figured out years ago.
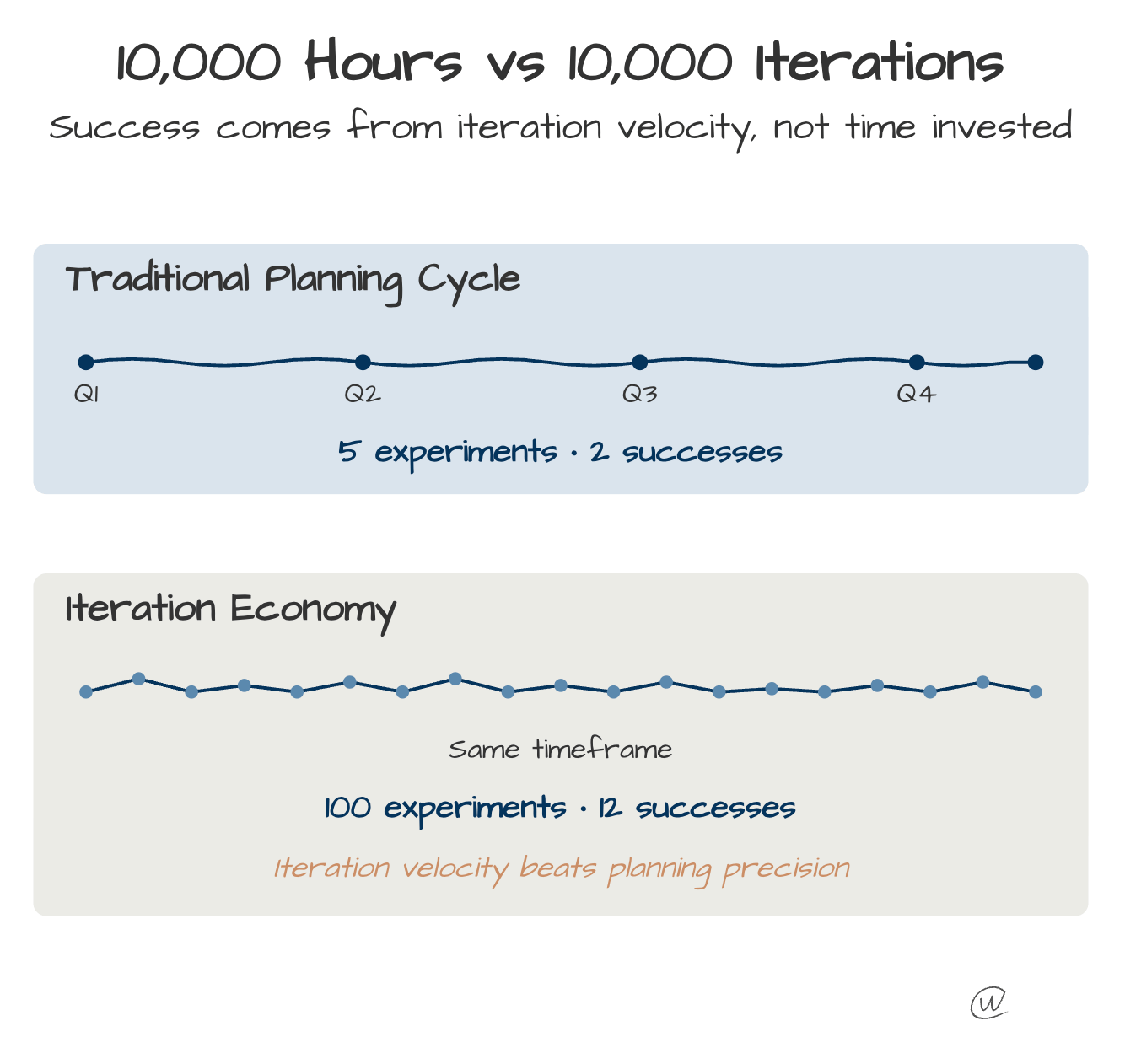
Outliers come from 10,000 iterations. Not 10,000 hours.
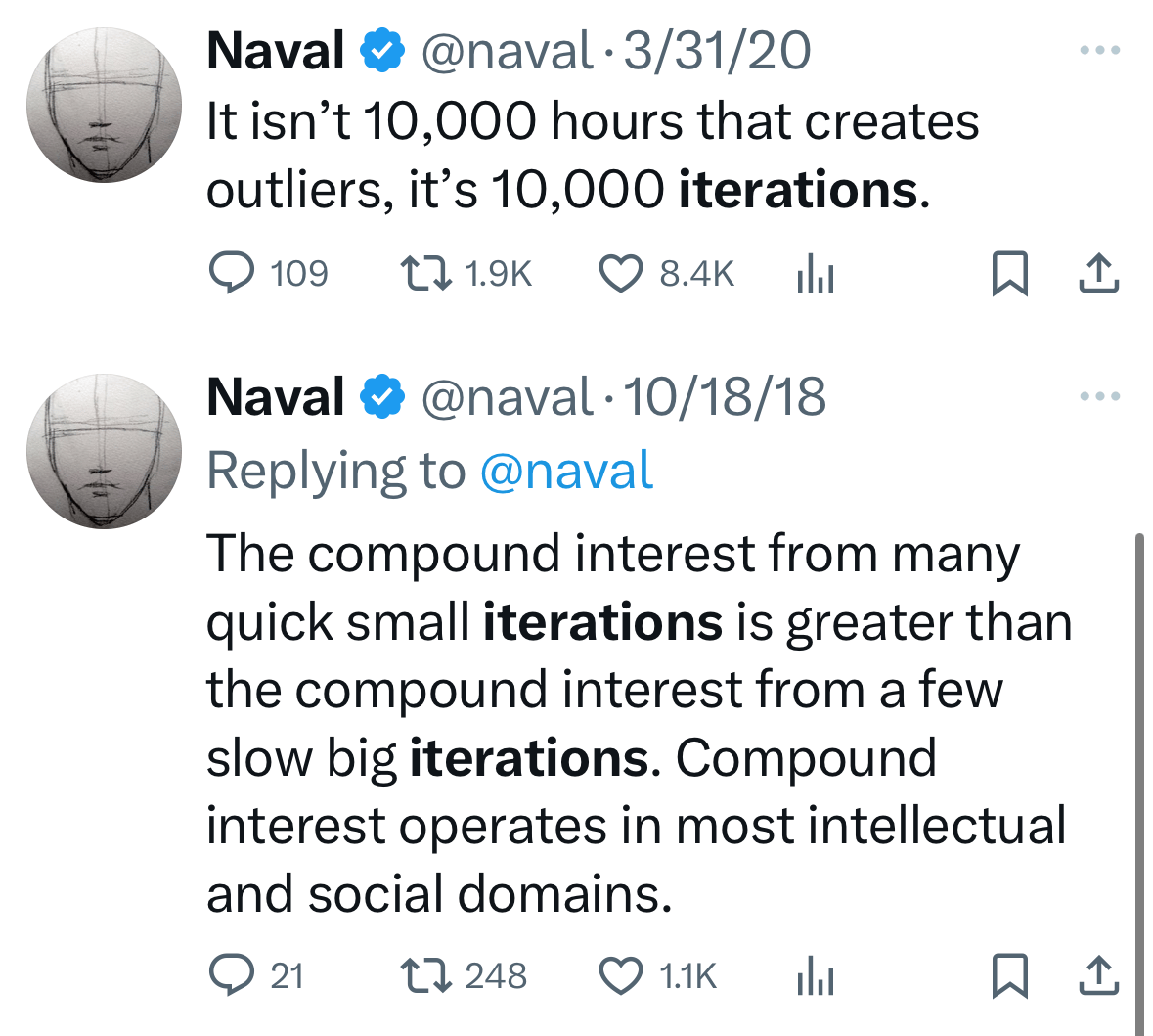
I love this. Success comes from iterative failure.
The compound returns from many quick experiments beat slow, perfect execution every time. And this last week just kept hammering that point home to me.
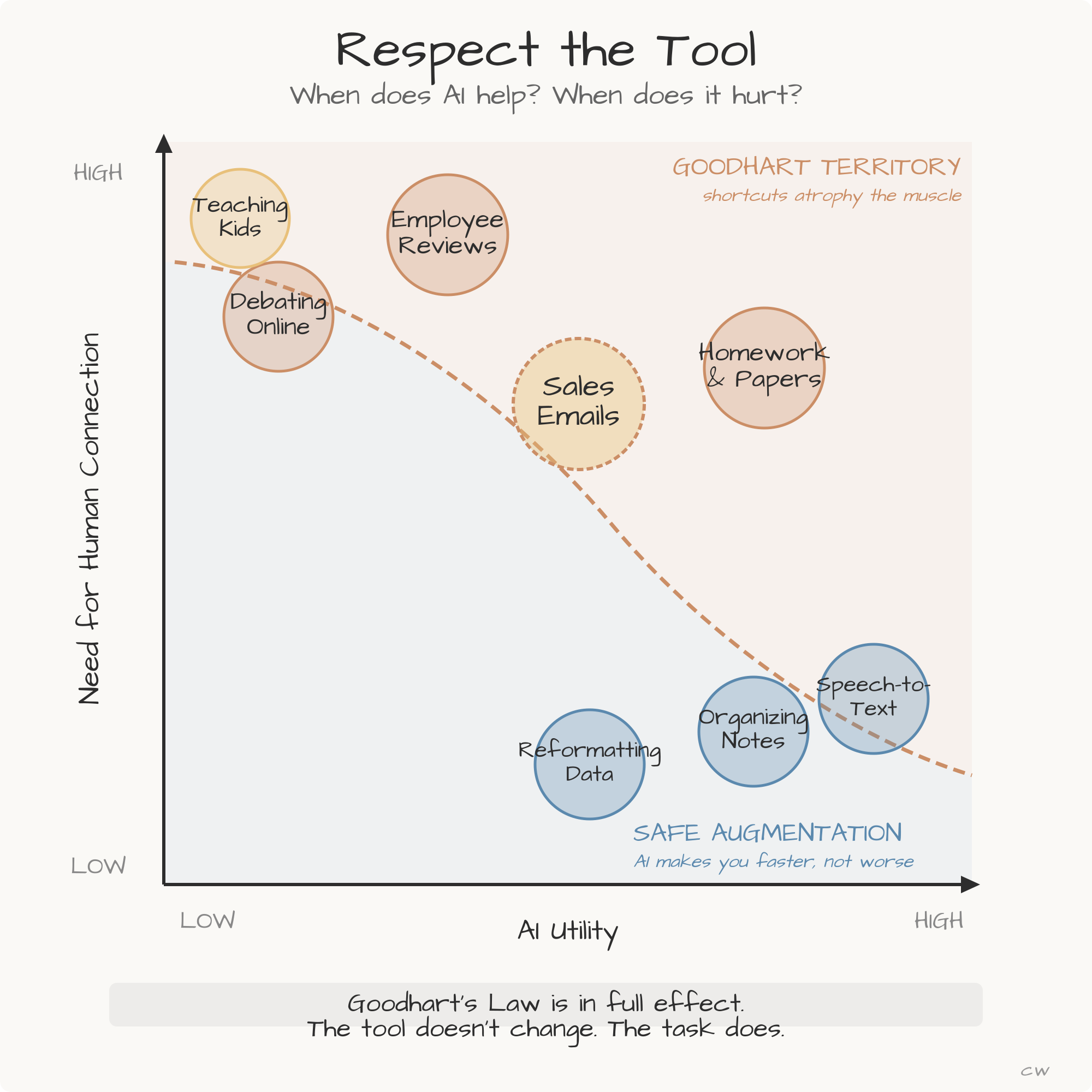
For the last 50 years, business has run on the Traditional Planning Cycle. You plan for a year, map it quarter by quarter, and run five big experiments. If you get two successes, you call it a win. This model rewards precision.
October 2025 is delivering multiple signals simultaneously, all converging on one conclusion: iteration velocity just became the only competitive moat that matters.
Google's quantum chip runs algorithms 13,000 times faster than supercomputers. Initial data suggests Anthropic's Skills framework is outpacing Model Context Protocol adoption by 6x. OpenAI is hiring 100 Wall Street bankers to iterate on finance workflows. Amazon is equipping delivery drivers with AR glasses to iterate thousands of route trainings.
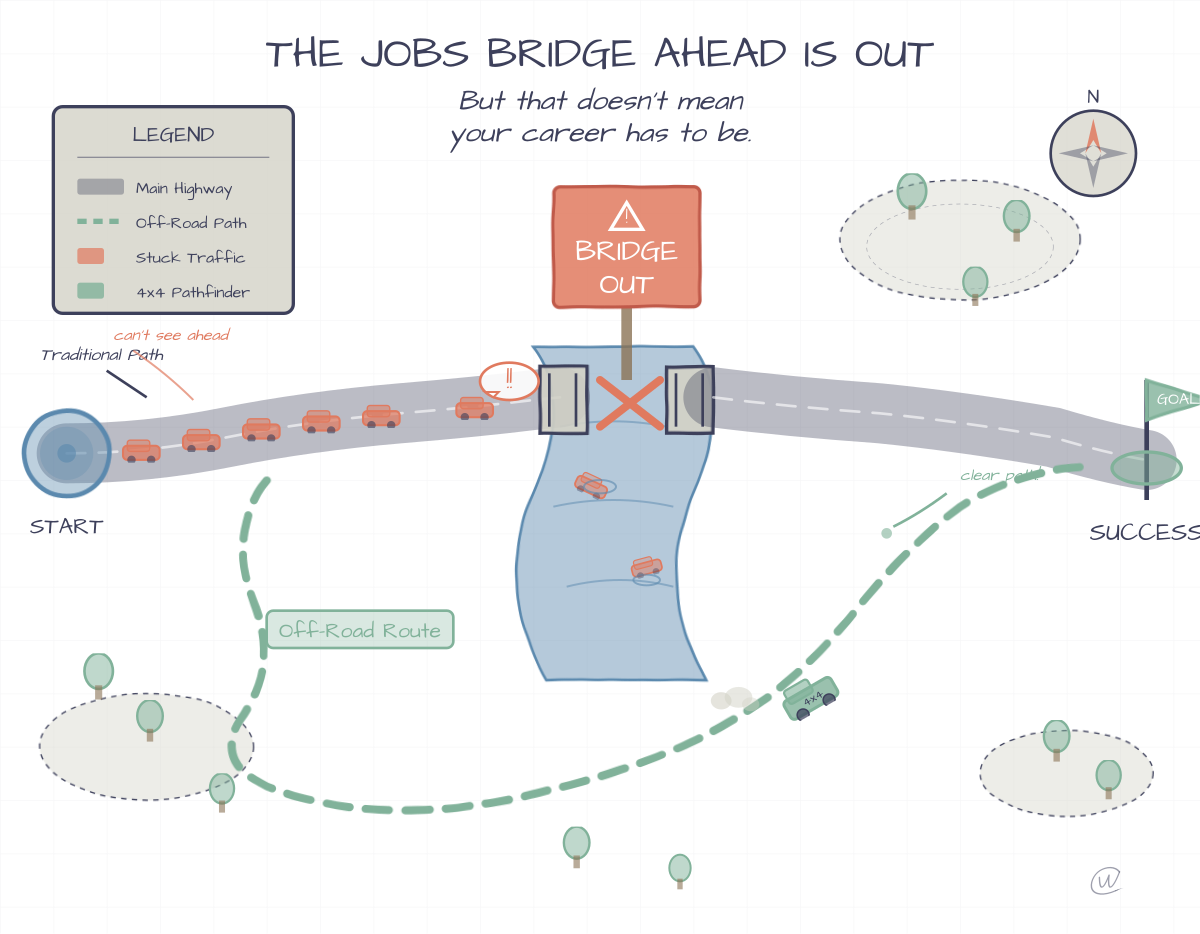
Your planning cycle now determines whether you survive.
The Iteration Economy is your only hope, Obi-Wan.
The Iteration Economy describes a market where competitive advantage comes from learning speed rather than resource advantages. Organizations win by running more experiments faster than competitors, not by executing better plans. When one company can test 100 approaches while another perfects one strategy, the first company accumulates knowledge that compounds into market dominance. Capital, talent, and technology still matter, but only as inputs to iteration velocity. The constraint that determines survival is how fast you can test, learn, and deploy the next version.
Let’s explore how all of these seemingly unrelated announcements from last week connect.

The 13,000x Moment
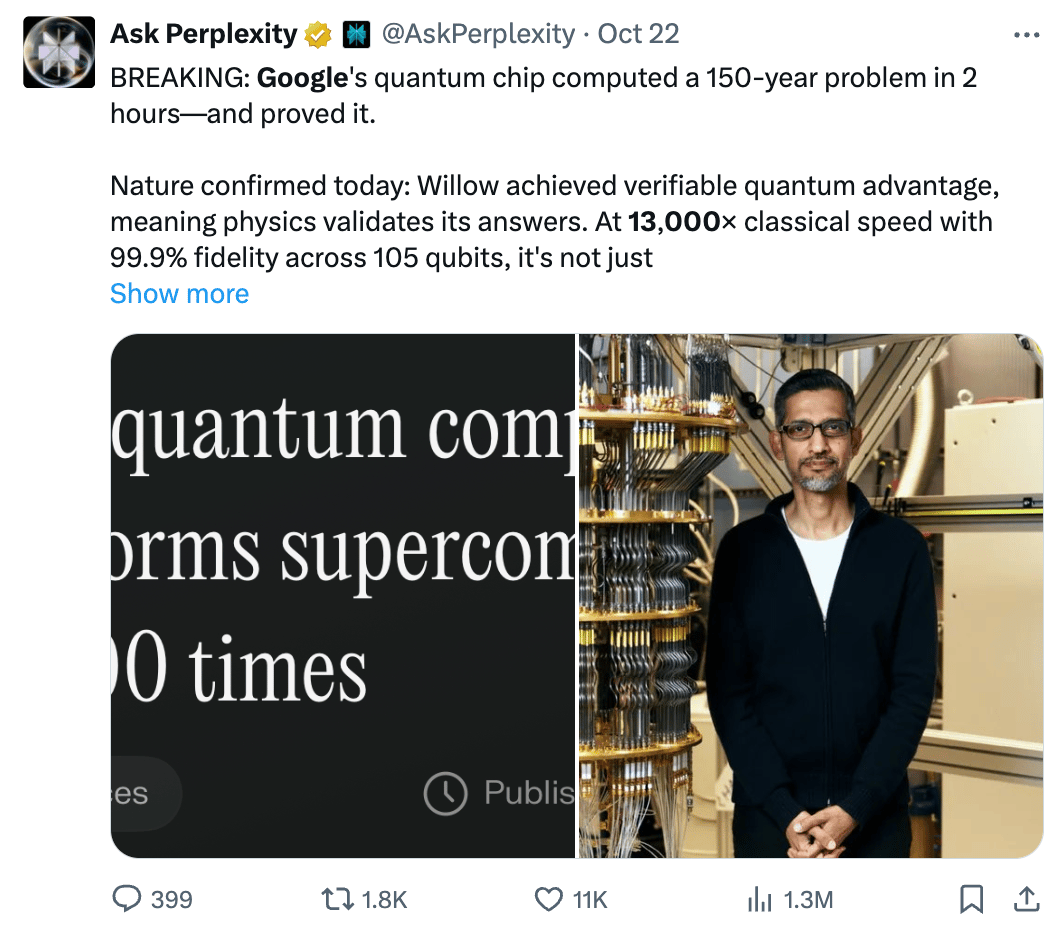
Google announced this week that its Quantum Echoes algorithm, running on the Willow chip, completed a physics simulation in just over 2 hours. The same calculation would take Frontier, the world's fastest supercomputer, approximately 3.2 years. That's a 13,000x speed difference.
I know this seems unrelated, but it’s not. I promise.
The breakthrough matters because compute scarcity is the single biggest bottleneck holding back AI adoption. That, and memory, of course.
There isn't enough ‘Compute’ for all the AI usage we want. Companies tend to ration AI access. Teams often limit experiments or run out of tokens fast. Basically, everyone operates under constraints.
Again, I know this Google breakthrough is nowhere near ready, but do we really think quantum computing or a similar construct won’t solve this problem?
Quantum computing isn't arriving next month. Google estimates practical applications in five years, and that timeline could stretch. But these results prove that the physics work.
When quantum systems scale to production, compute scarcity disappears. Everyone using AI gets unlimited compute and iteration speeds beyond anything we can currently imagine. If we can iterate ideas, compounds, financials, statistics, and probabilities at 13,000 the speed and efficiency of today… what does that do for all business decisions?
The Market Already Moved
The "Iteration Economy" is only possible because AI has collapsed the cost and time of an individual iteration to near zero. Let’s dive into more examples.
This week, there was a lot of noise around Antropic's new “Skills.”
Initial data suggests that this new capability from Anthropic is outpacing adoption of their Model Context Protocol (MCP) by 6x, as teams can start iterating within hours of installation. Faster integration means faster learning cycles. Teams using Skills run dozens of experiments while MCP users are still configuring their first implementation.
Essentially, the barrier to adoption is much lower for Skills, and they also enable asynchronous scaling in a standard prompt. This is a huge win for any of you (like me) who regularly run out of memory in your context window.
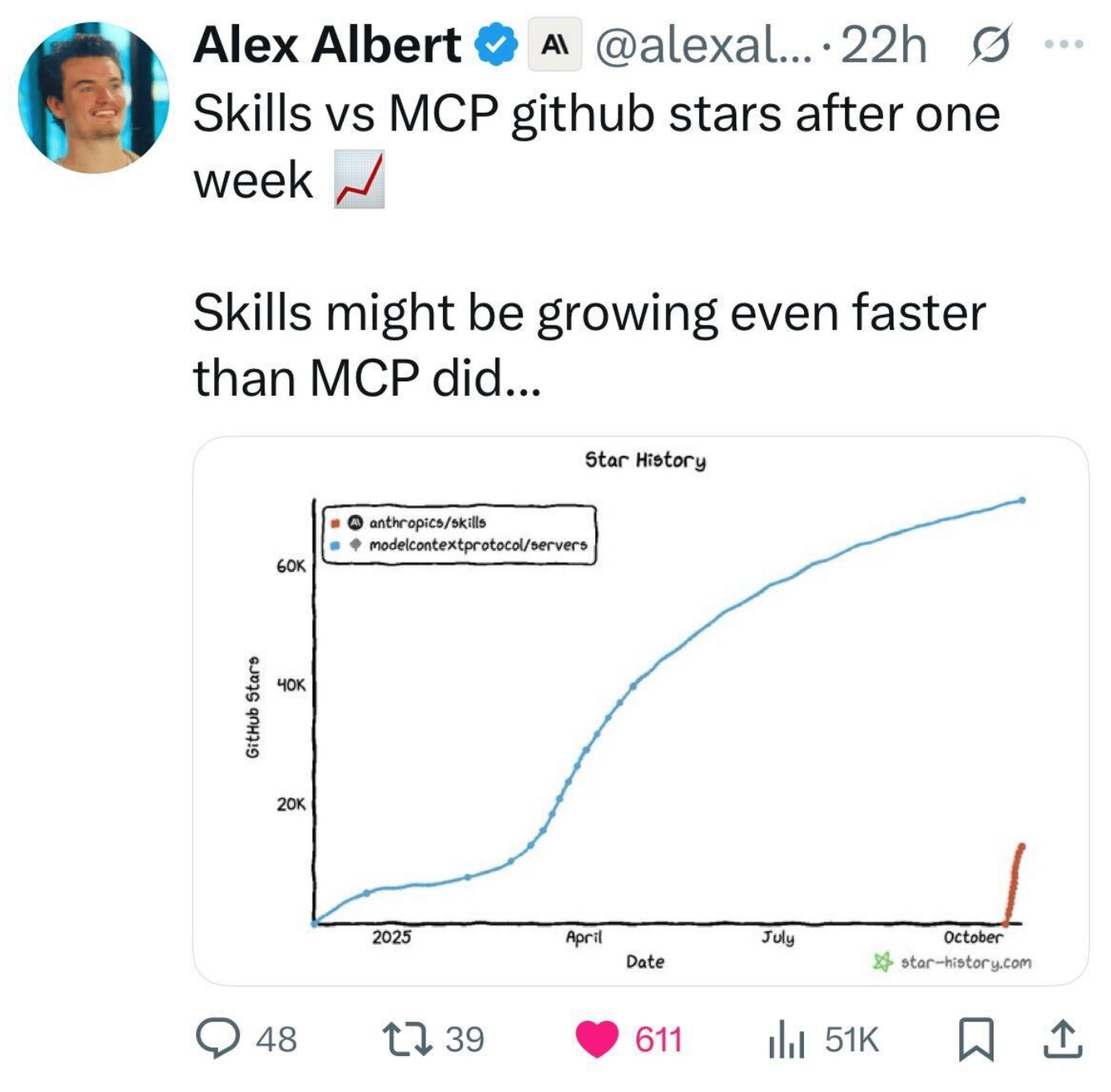
Yes, “stars” are not a perfect indicator, but Yelp is still worth over $2B.
Here’s another one.
In a weirdly personal development, OpenAI's Project Mercury has recruited more than 100 former investment bankers from Goldman Sachs, JPMorgan, and Morgan Stanley.
I started my career as an investment banking analyst, and $150 per hour was WAY more than I was paid. This is mainly because, as salaried employees, we’d run 70- to 90-hour workweeks.
OpenAI is purported to be paying these analysts $150 per hour to generate high-quality training data through repeated financial modeling exercises.
Each ‘banker’ creates dozens of models per week, building a training dataset that competitors spending months on perfect AI architecture can't match. The iteration velocity on training data beats architectural sophistication.
If 100 former bankers hammer enough typewriters for enough time…
Next, Amazon is deploying AR glasses to delivery drivers through its Amelia project.
The glasses capture tens of thousands of recordings every single day, generating training data at a scale competitors can't match. This feeds continuous iteration on navigation, obstacle detection, and delivery optimization. While competitors run pilot programs, Amazon will be able to process millions of real-world delivery scenarios daily.
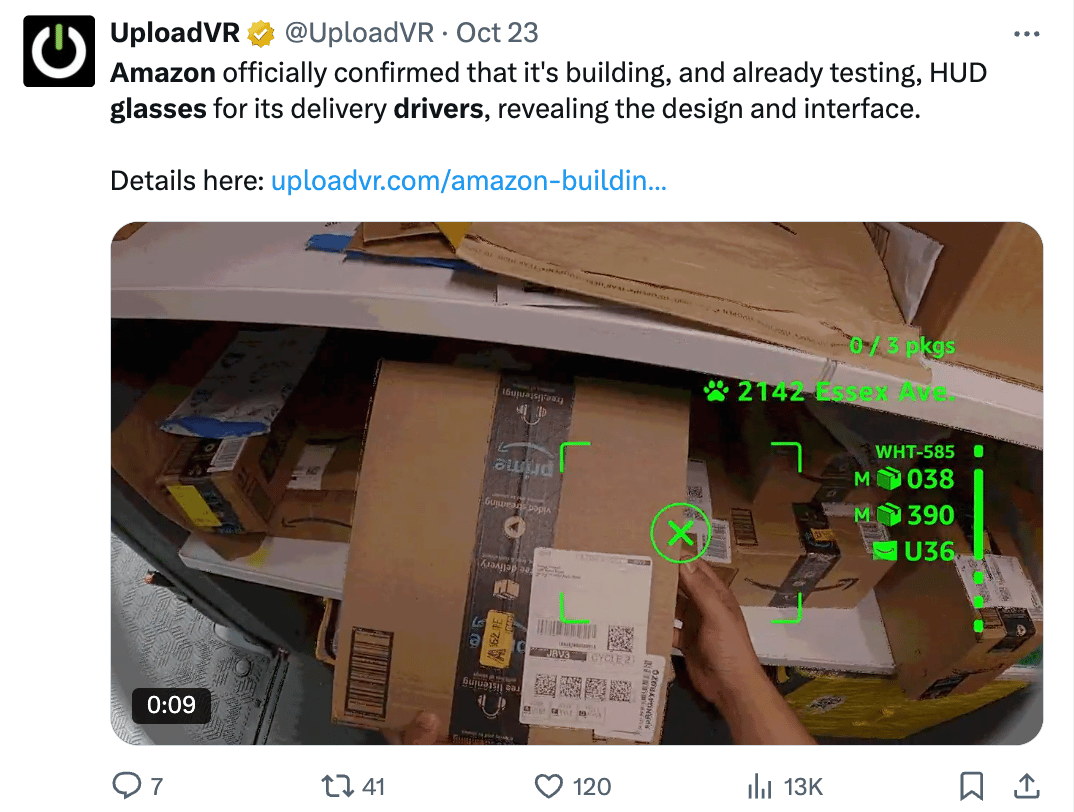
I used to load the vans at UPS at night, and these would have been amazing.
Last, and probably most significant to an iteration mindset.
OpenAI just launched ChatGPT Atlas, a full browser. Every search, every page visit, every tab interaction becomes training data. The browser captures consumer engagement at a scale chat applications can't touch.
While competitors iterate on conversation data, OpenAI is iterating on how hundreds of millions of people actually browse, search, and consume information across the entire web. This all keeps speeding up, faster and faster.

Installed and testing.
So that’s FIVE examples of technologies that seek to either:
a) gather more data, faster, at scale to be analyzed asynchronously, or
b) advancements in using AI and Compute that make iteration faster on that larger data set.

This is the SpaceX Playbook at Scale
SpaceX failed more times than Boeing tried. Falcon 1 blew up three times before the fourth launch succeeded, saving the company. Blue Origin started two years earlier with comparable resources but chose perfection over velocity. SpaceX won by iterating through failures faster than competitors could plan single launches.
The playbook is simple: measure iteration in days. Run a forensic analysis on every failure. Deploy the next version before competitors finish their design review.
By the time traditional aerospace approved a change, SpaceX had tested, failed, learned, and shipped version 2.
This model now applies to everything.

Companies moving at iteration speed are outrunning every system now.
For example, legal systems are designed for slower markets. Google just beat the Department of Justice's antitrust case by citing new AI search technologies as proof they're no longer a monopoly. The irony is that many of those technologies didn't exist when the DOJ filed the case (in October 2020).
The market iterated faster than the legal process could keep up.

Your Planning Cycle Is Your Liability
If your competitor can run 10 experiments to your one, they don't need to be smarter.
They only need one breakthrough while you're still refining your perfect plan.
Quarterly planning assumes everyone operates on the same timeline. That assumption is dead.
Every quarter you spend on roadmaps gives competitors time to run 50 experiments and collect data from millions of interactions. Organizations optimized for stability and process built those systems when everyone moved at comparable speeds. Now those same systems create paralysis.
Amazon's delivery glasses will fail in ways no planning committee can predict. Each failure generates data that they can then optimize from. Competitors study pilot programs for months while Amazon processes millions of deliveries daily and ships version 47 based on actual field data. (They’re also going to train an army of delivery robots from this data.)

Build Iteration Infrastructure Now
Stop optimizing your AI model (it will never beat the incumbents) and start optimizing your iteration clock.
How many experiments can you run this week?
If the answer is < 1, you're not doing this right. I’m very fortunate to work in an environment where we have simultaneous design, data, utilization, and AI experiments firing. Every day. But it still doesn’t feel like enough.
So here are some ideas to consider in your organization:
Audit your decision-making speed. Track actual time from idea to production deployment. Every approval layer adds time to the time competitors spend iterating. Document where your process creates delays. And heck! Maybe even let your engineers skip product and build things first!
Hire for velocity over strategy. The people who win run three experiments by Tuesday. Look for those who've shipped 30 imperfect solutions rather than those who've spent years perfecting two.
Create separate teams with different risk profiles. One team optimizes existing systems with zero tolerance for failure. Another team runs high-volume experiments where failure generates data. Both teams share insights regularly.
Measure the iteration rate above the success rate. I know, you won’t do this one… but hear me out. Try to track how many experiments you run, not just how many succeed. Most companies aren’t wired this way, but I promise you, the ones that prosper the next three years will.
The Bottom Line
Build systems that let you test, measure, and kill failures in days.
Or watch companies with worse products outrun you by running 50 experiments while you plan your first.