The 1% Problem (of AI Errors)
Better AI Accuracy Makes Errors Harder to Catch, Not Easier
Christian J. Ward
Dec 18, 2025
In last week's post, The Verification Trust Problem, I argued that trust is the currency of AI.
If you cannot trust your AI, you stop using it. But as these models scale, a new problem has emerged.
The recent release of Claude Opus 4.5, Nano Banana Pro, GPT-5.2, and Gemini 3 within thirty days has changed what we expect from AI capability. These models are good enough that detecting hallucinations has become genuinely difficult.

The Hallucination Decline
In the early days of GPT-3.5 and GPT-4, you could often spot a hallucination because the tone would change, the slop would appear, or the logic would fray. It felt incorrect, like a glitch that human intuition could flag.
That intuition is becoming unreliable.
OpenAI's latest technical report on GPT-5.2 documents a 50% decline in hallucinations compared to previous generations. This is statistically impressive, but it creates a false sense of security. When a system is right 99% of the time, we stop checking. We become complacent. And that is precisely when the 1% error rate becomes the bottleneck.
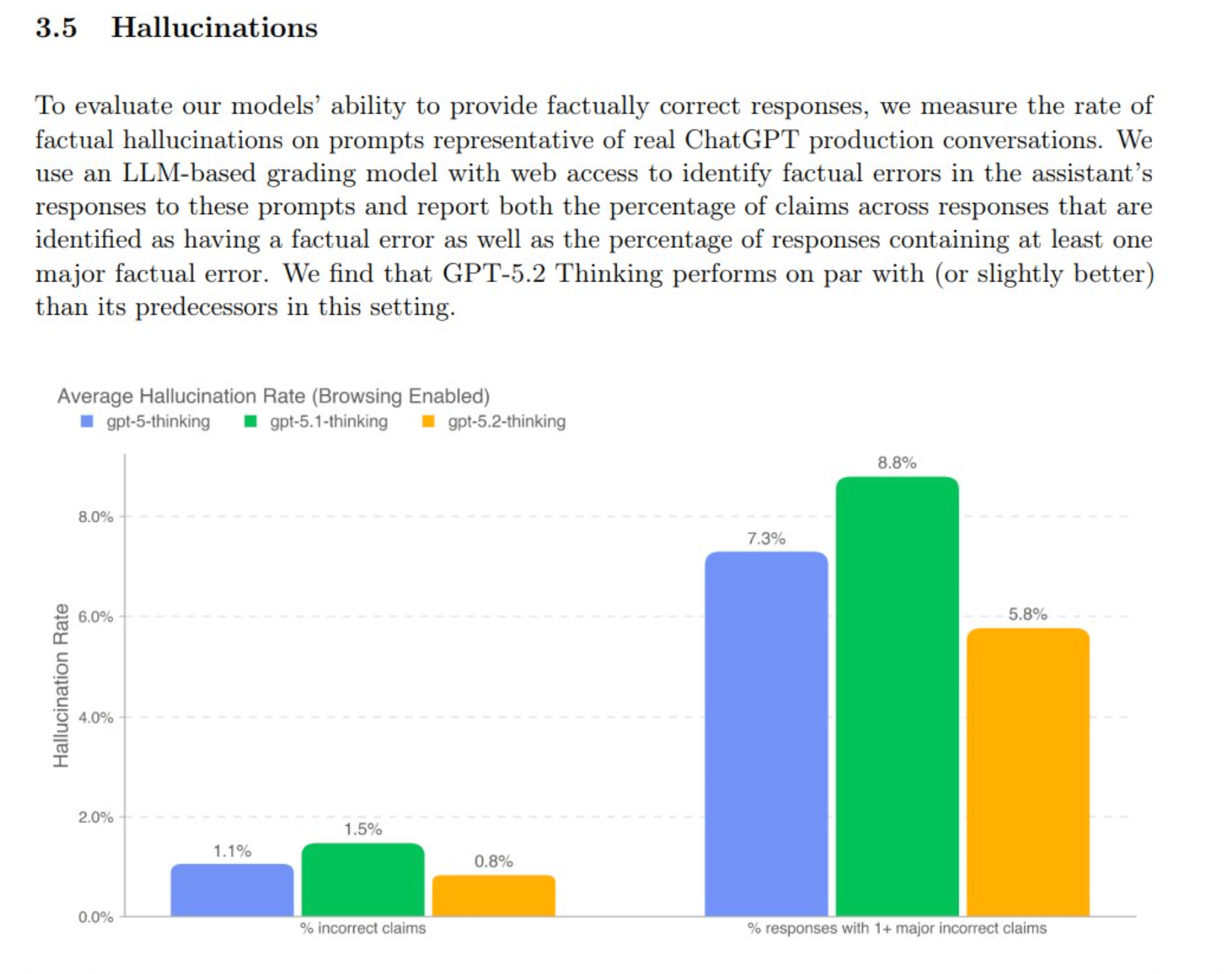
At .8% and 5.8% - this continues to improve quickly.
Sam Altman posted about the model's gains, and he’s correct.
But we need to highlight that in previous generations, errors often announced themselves through broken logic or tonal changes. That signal is disappearing as models become smoother. External verification protocols are no longer optional.

The Verification Pipeline
If human intuition can no longer serve as the primary filter, we need structural confidence intervals built into the AI response itself. We need a Verification Pipeline.
Instead of treating verification as a final fact-checking step, think of it as a multi-stage architecture that filters information based on verifiability.
This implies that we need distinct paths in which specific query types trigger specific verification protocols.
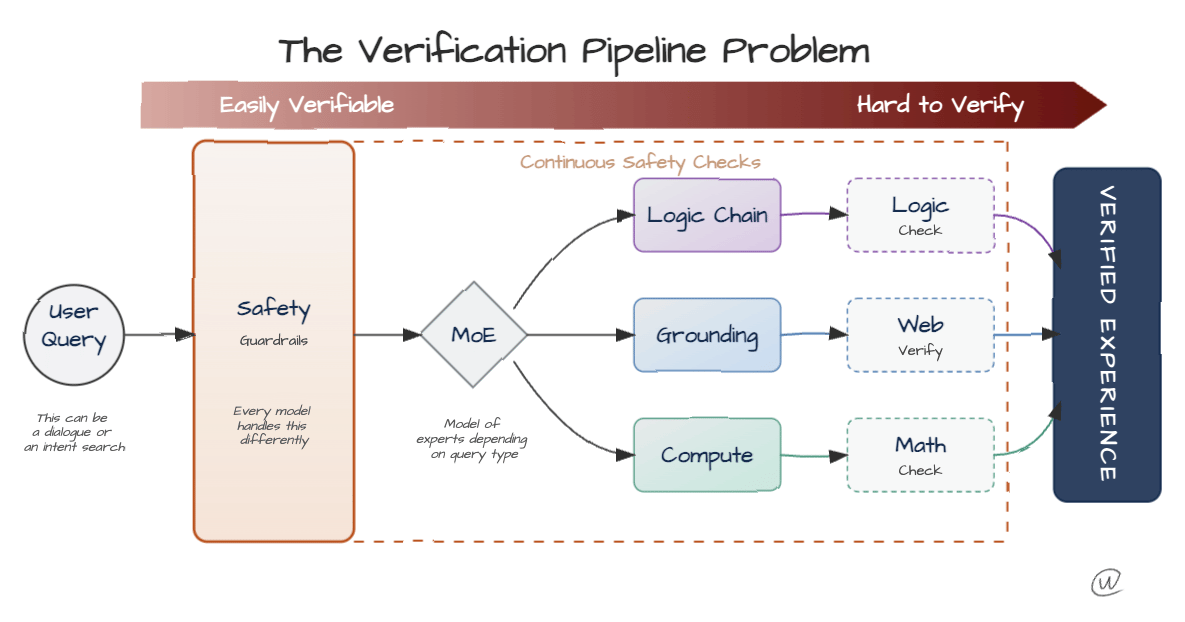
This is only conceptual; you don’t need to verify it.
Stage 1. Safety Guardrails
At the beginning, we have the coarsest filter. Strict safety checks that operate as a binary gate. Is this safe and allowed? Every model handles this differently, but it must be enforced before any processing begins and throughout every stage thereafter.
Stage 2. MoE Routing
Once past the guardrails, the query hits the Mixture of Experts router. This is where context matters. Does this query require a math expert, a creative writer, a coding assistant, or does it require live data?
The router determines the verification path, deciding whether the query requires a logical chain for reasoning or a computational solver for more deterministic answers.
For reasoning tasks, the model engages in a chain of thought processes to validate the argument. For mathematical or code-based queries, the request is offloaded to a computational solver that provides a deterministic answer. Each step here will require a different verification approach.
Stage 3. Compute, Grounding, and Human Verification
This is the final and most involved stage. If the query requires facts, the model cannot simply rely on training data. It must engage in grounding, and this goes beyond simple web searches.
I’ve drawn this as three choices, but it’s likely much larger than that, with varying degrees of verification, also by topic. What medication is in that bottle you took a photo of better have different levels of verification than whether that teddy bear you took a photo of will make a good gift.
This stage involves querying internal data sources, cross-referencing against the open web, and looping in the human user for clarification when ambiguity remains. A proper verification system does not just guess. It asks "Did you mean this?" to narrow the scope.
Soon, it will not just look for an answer, it will look for corroboration.

The Verification Playbook
Given this, how do we actually verify?
Think of the current class of models not as a database, but as a capable assistant who is new to your industry. They lack the specific historical context but can find answers if given the right tools. You would not trust the new person blindly. You would check their work.
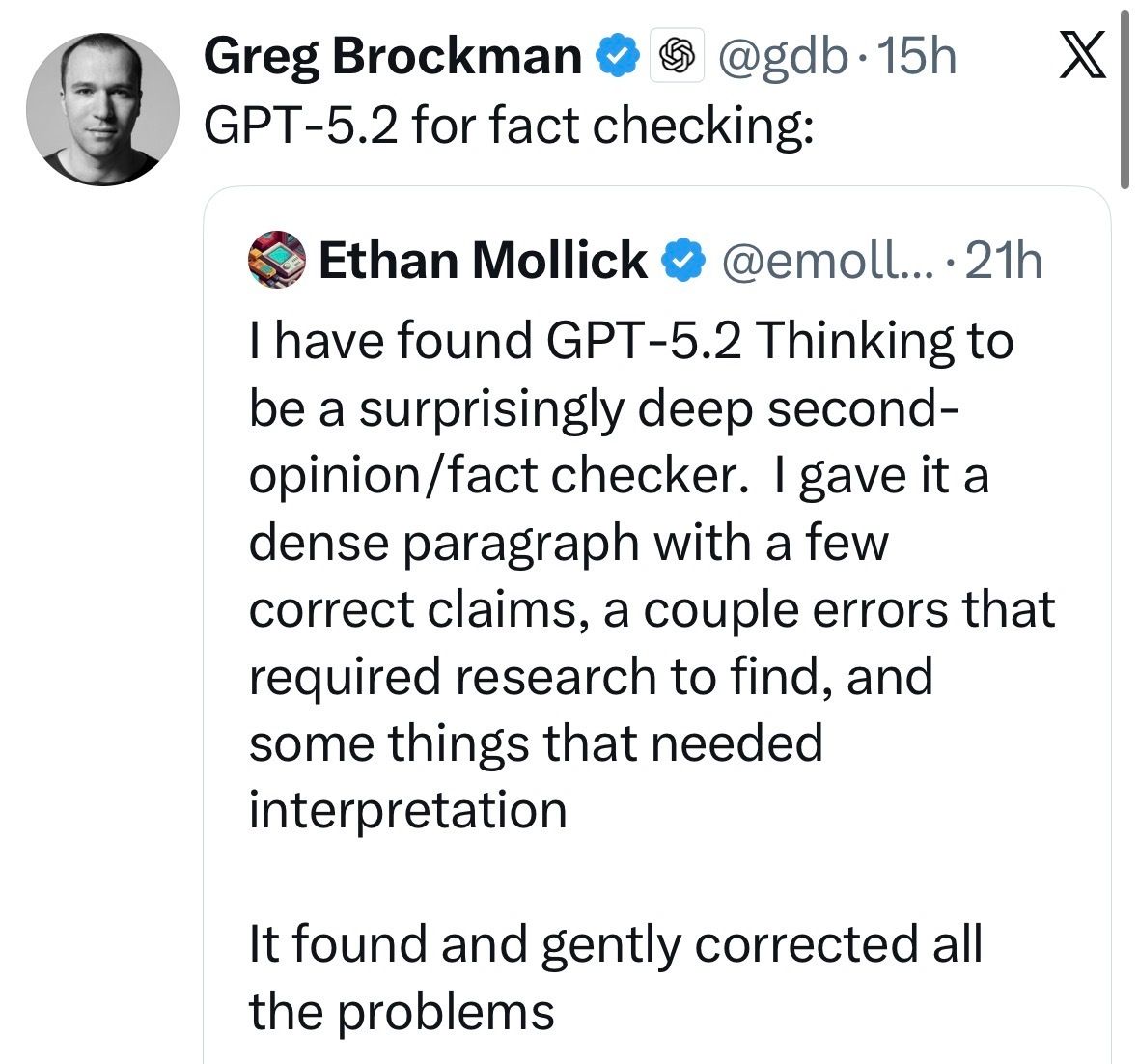
“Gently” corrected all problems. Something Deadpool would say.
Here are Five Strategies to build a verification habit.
The Knowledge Gap Strategy. If you are using Claude, turn off web search. This forces the model to rely on its training data. If it cannot answer, you know the information is not "known" to the model, protecting you from a hallucinated web summary.
Cross-Model Auditing. Use one model to police another. Feed a Gemini output into GPT-5.2 and ask it to verify those claims. The friction between two different training runs often exposes errors.
Tabular Verification. Ask the model to format the data into a table with specific columns. Hallucinations often hide in paragraphs but stand out in rows. If a cell is empty or looks generic, that is your target for checking.
Confidence Scoring. Ask the model to assign a confidence score to its answer. Be specific and request a confidence percentage. In my testing, a score above 80% is generally reliable. I have found that a score of <50.1% is a reliable signal that the model is guessing (that’s a joke, get it?).
Deep Research Mode. For involved topics, engage Deep Research modes. This forces the model to gather citations from a broader array of sources, creating a bibliography you can audit.
The Verification Requirement
We are moving toward a tiered verification system because different data requires different levels of corroboration.
When I ask about a business and whether it is open, that has one level of verification because there are many sources to corroborate that information.
When I ask whether the business has a certain product, that is a different level of verification because there may not be as many corroborating sources beyond the business itself.
And if I ask whether the business has an offer or a deal, there may be only one source because the business makes that offer available in real time.
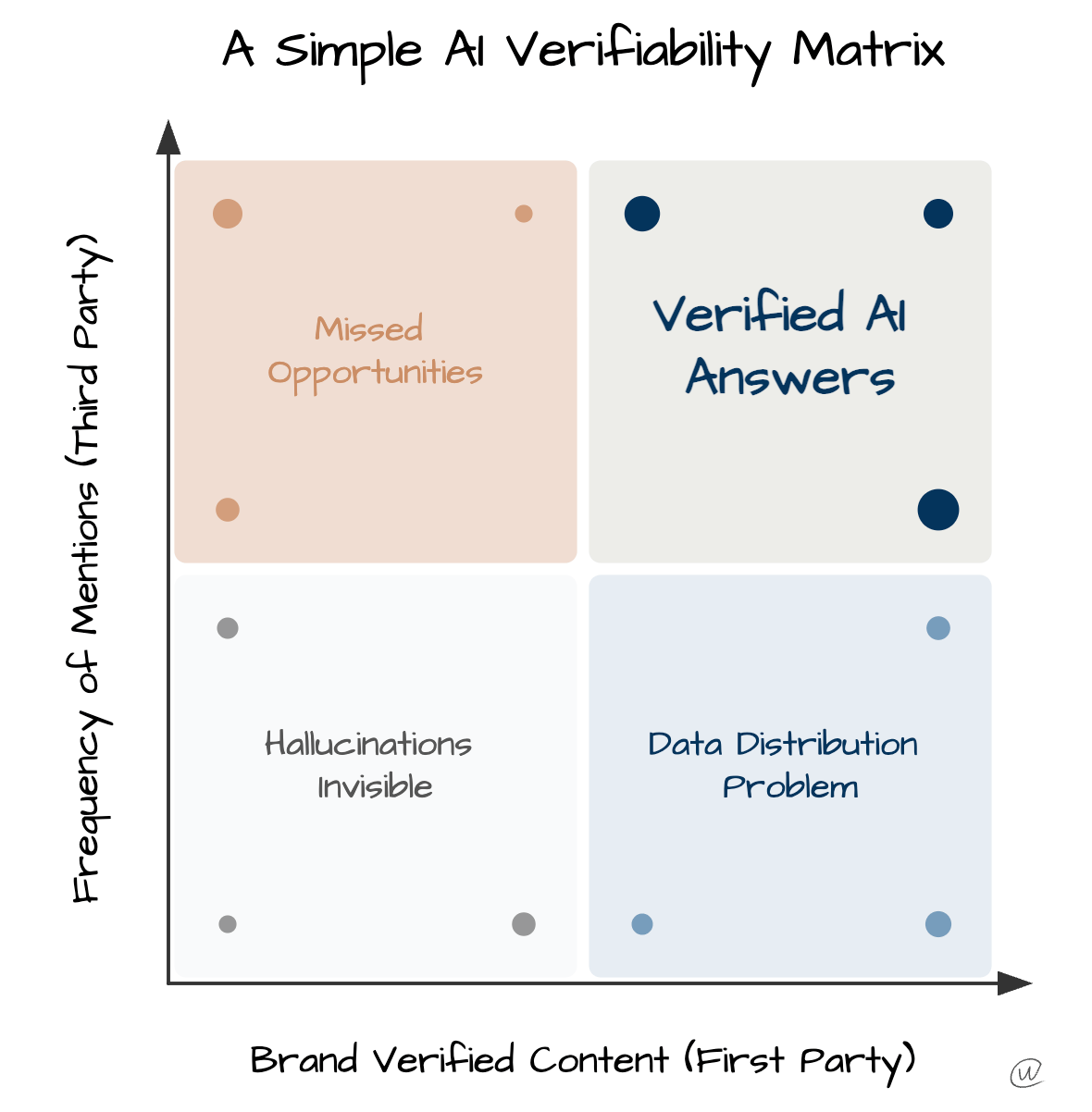
This means that, as businesses try to keep their data verifiable, they have to consider real-time data corroboration across the ecosystem. Putting business data in as many places as possible, synchronized and distributed in real time, is one of the only ways to help search engines validate sources. We know this helps ranking in Google. With AI, this need for verification will be much higher.
What's Next
I am working on a guide exploring some of these validation and verification processes with AI. It will cover the practical workflows to get verification into your workflow in a more concrete way.
Stay tuned.