From the Newsletter
The Second Brain Finally Works
After Years of Trying, LLMs Made Knowledge Graphs Actually Usable
I have been trying to build a personal knowledge graph for close to eight years.
It has never worked.
Until now.
Andrej Karpathy posted this week about using LLMs to build personal knowledge bases. He said a large fraction of his recent token throughput is going into manipulating knowledge, stored as markdown and images, rather than manipulating code.

I've been working on the same thing for the last year, but it's been a helluva journey.
It started around 2018. Roam Research, then Reflect, then a handful of others I won't bore you with.
Each one promised networked thought.
Each one worked until the network got big enough that I stopped maintaining it.
The problem was never the tools.
The problem was me. I would never keep up with the linking.
About a year ago I moved everything into Obsidian and started treating it as a knowledge graph instead of a note-taking app. People, companies, products, projects, meetings, voice notes, and the connections between all of them.
My son says it looks like a planet when you zoom out. He's not wrong.
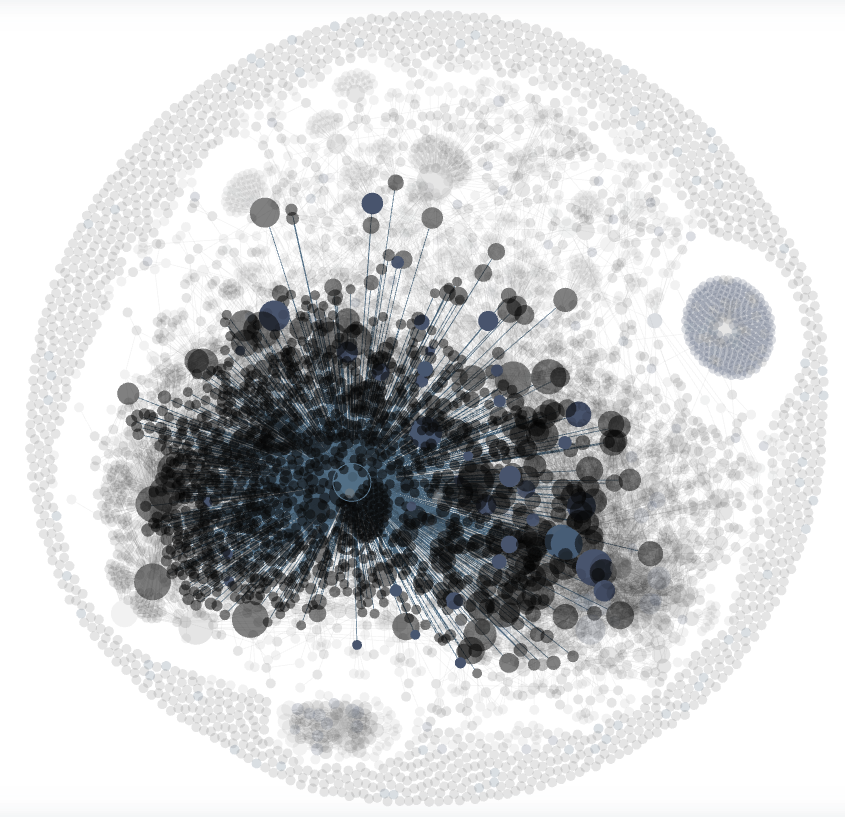
The difference this time is that I stopped organizing it.
The system does that. And it starts with my voice.
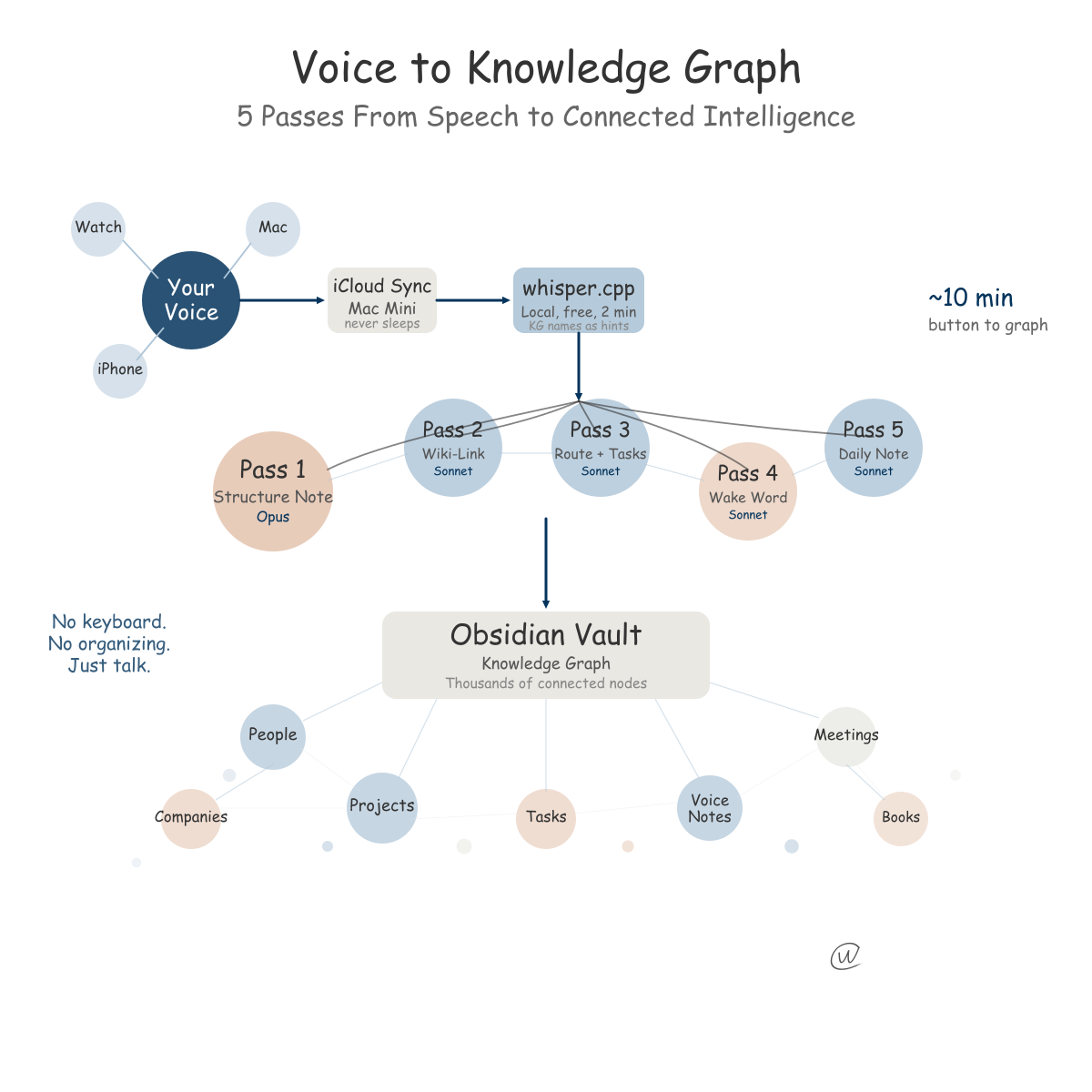
My pipeline is designed to be async. I capture thoughts on my Apple Watch, my iPhone, or my Mac using Just Press Record.
One button. I talk for as long as I need to, then press the button again.
Sometimes it's five minutes while walking the dog. Sometimes it's forty minutes pacing my backyard, working through a business strategy.
Every once in a while, my wife thinks I'm nuts because I'm talking into my Apple Watch and she doesn't realize I'm not on a call. It reminds me of Michael Knight in Knight Rider, played by David Hasselhoff, who talked to his computer car AI, K.I.T.T.
But I digress.
It also lets you interview people, which I've found fun.
If we're talking about using AI at our local pub with friends, I will often ask if I can interview them with a series of questions on my watch.
By the time I'm home, the pipeline has processed the audio, and we have either a business plan or an AI strategy document waiting for them, based on their answers.
It's pretty amazing.
All three devices sync through iCloud to my Mac Mini, which never sleeps. It runs a watcher process that monitors the folder around the clock.
For transcription I use whisper.cpp on the M4 chip. No API call, no cost, about two minutes for a thirty-minute recording.
And it does something I'm proud of. It feeds every person and company name from my knowledge graph into Whisper as spelling hints, so names like "Ahearn" or "Wardwells" come out right.
From there, the transcript enters a pipeline running through Claude on the Max subscription.
The first thing Claude does is the creative work. It reads the raw transcript, pulls the signal from the rambling, and produces a structured note with a title and category.
I run this on Opus because the quality of that first interpretation sets the ceiling for everything downstream.
Then comes the linking. Claude wiki-links the note against every entity in the vault. If I mentioned a person, that name becomes a clickable link to their entity file. If I referenced a project, same thing.
Not because I sat down and connected things. Because it happens every time I talk.
Claude also extracts tasks and routes new context to the right entity pages. If I said "I need to follow up with Sarah about the pricing model," that becomes a task.
About three months in, I typed the name of someone I hadn't spoken to in two years.
A former colleague.
I expected maybe one or two old notes. Instead the graph surfaced fourteen connections. Meeting notes from 2022, a product idea we had discussed in a voice memo I had forgotten about, two other people who always appeared in the same conversations, and a project thread that connected to something I was working on right now.
I sat there staring at it.
It had been building context I would never have maintained manually.
Not organization. Memory I didn't know I had.
If, during a recording, I say something like "Can you write a first draft of the onboarding plan based on everything we discussed this week," the pipeline detects that instruction and spawns a separate Claude session to execute it.
Last Tuesday, I did this at 11 PM while putting the dishes away.
When I opened my laptop on Wednesday morning, the draft was sitting in a folder.
Twelve hundred words, pulling from four separate voice notes across the week.
I can leave instructions for AI inside a voice recording, and they get carried out through the pipeline.
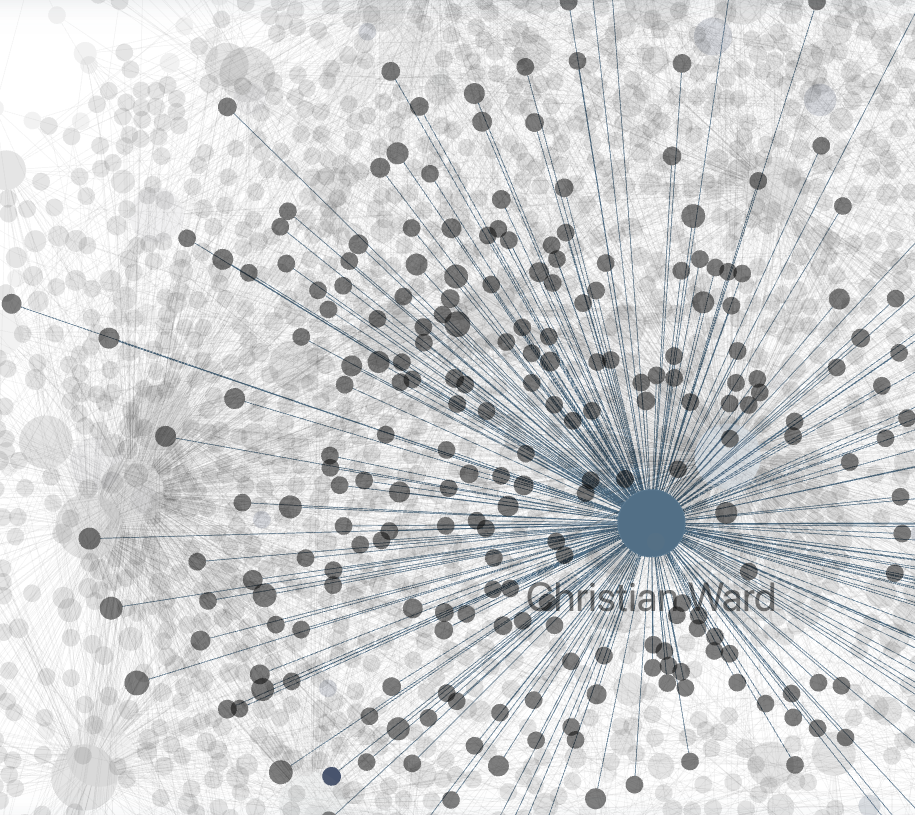
Karpathy is spending more time building knowledge bases than writing code. That tells you where we are.
The stack costs almost nothing
Obsidian is free. whisper.cpp is open source. Claude on the Max plan costs the same whether you run zero pipelines or fifty.
I've been doing this for a year now, and it keeps growing.
If you've always wanted a second brain, start now. It works.
Get More Where This Came From
Weekly AI frameworks and data strategy for people who have to make the call.


